
使用 CF2OpenAI 将 Cloudflare Workers AI 转换为 OpenAI 兼容接口

使用 CF2OpenAI 将 Cloudflare Workers AI 转换为 OpenAI 兼容接口
三水番项目简介
CF2OpenAI 是一个部署在 Cloudflare Workers 上的轻量级 API 适配器。它的目标很明确:把 Cloudflare Workers AI 的接口包装成 OpenAI Chat Completions 风格,让支持 OpenAI API 的客户端、SDK 或插件可以直接调用 Cloudflare 提供的模型。
换句话说,如果某个工具只允许填写 API Base URL、API Key 和 Model,那么部署 CF2OpenAI 后,就可以把这个工具接到自己的 Worker 地址上,再由 Worker 转发到 Cloudflare Workers AI。
项目整体非常精简,当前仓库主要包含:
1 | CF2OpenAI/ |
从结构上看,它不是一个传统 Node.js 项目,仓库中没有 package.json、wrangler.toml 或复杂的构建流程。核心代码集中在 _workers.js,更适合直接复制到 Cloudflare Dashboard 的 Worker 编辑器中部署。
项目背景与用途
Cloudflare Workers AI 提供了托管模型推理能力,并且可以和 Cloudflare Workers、Pages 等产品自然集成。但很多现成客户端默认支持的是 OpenAI API 协议,例如:
- OpenAI SDK;
- 各类 AI 聊天客户端;
- 支持 OpenAI Chat Completions 的编辑器插件;
- 自建 API 网关或模型聚合工具;
- 只暴露
base_url、api_key、model三项配置的软件。
CF2OpenAI 解决的就是协议适配问题:客户端仍然按 OpenAI 的格式请求 /v1/chat/completions,Worker 接收请求后再调用 Cloudflare 的 OpenAI 兼容端点。
这样做的好处是:
- 客户端侧不用为 Cloudflare Workers AI 单独写适配代码。
- 可以用统一的 OpenAI SDK 调用 Cloudflare 模型。
- API Key 由自己定义,避免直接把 Cloudflare API Token 暴露给客户端。
- 部署在 Cloudflare Workers 上,不需要额外准备服务器。
核心功能
结合 README 和 _workers.js 源码,CF2OpenAI 的核心功能主要有以下几类。
1. OpenAI 风格接口
项目实现了两个主要端点:
| 端点 | 方法 | 用途 |
|---|---|---|
/v1/models |
GET |
返回当前 Worker 内置的模型列表 |
/v1/chat/completions |
POST |
接收 OpenAI Chat Completions 格式请求并转发到 Cloudflare |
这意味着大多数支持 OpenAI Chat Completions 的客户端,只要能自定义接口地址,就可以尝试接入。
2. 流式和非流式响应
客户端可以通过请求体中的 stream 字段控制是否流式输出:
1 | { |
源码中并没有手动拆分 SSE 数据,而是直接透传 Cloudflare 返回的响应体。非流式响应通常是 application/json,流式响应通常是 text/event-stream,Worker 会保留 Cloudflare 返回的 Content-Type,并在流式模式下附加 Cache-Control: no-cache 和 Connection: keep-alive。
3. 模型短名称映射
Cloudflare Workers AI 的模型名称通常类似:
1 | @cf/meta/llama-3.1-8b-instruct |
为了让客户端配置更简单,CF2OpenAI 在 _workers.js 中维护了 TEXT_GENERATION_MODELS 映射表。用户在客户端填写短名称,例如:
1 | llama-3.1-8b-instruct |
Worker 会自动映射为:
1 | @cf/meta/llama-3.1-8b-instruct |
当前源码中包含的模型示例有:
| 客户端短名称 | Cloudflare 模型路径 |
|---|---|
llama-3.1-8b-instruct |
@cf/meta/llama-3.1-8b-instruct |
llama-3.3-70b-instruct-fp8-fast |
@cf/meta/llama-3.3-70b-instruct-fp8-fast |
llama-4-scout-17b-16e-instruct |
@cf/meta/llama-4-scout-17b-16e-instruct |
deepseek-r1-distill-qwen-32b |
@cf/deepseek-ai/deepseek-r1-distill-qwen-32b |
gemma-7b-it |
@hf/google/gemma-7b-it |
mistral-7b-instruct-v0.2 |
@hf/mistral/mistral-7b-instruct-v0.2 |
kimi-k2.5 |
@cf/moonshotai/kimi-k2.5 |
kimi-k2.6 |
@cf/moonshotai/kimi-k2.6 |
如果请求中的模型短名称不在映射表中,源码会回退到默认模型 llama-3.1-8b-instruct。这能避免请求直接崩掉,但也意味着填错模型名时可能会悄悄变成默认模型,排查时要注意日志。
4. 自定义 API Key 鉴权
CF2OpenAI 会检查请求头:
1 | Authorization: Bearer sk-你的自定义密钥 |
只有 Bearer Token 与 Worker 中配置的 API_KEY 一致,才会继续处理请求。这样客户端不需要知道 Cloudflare 的 Account ID 和 API Token。
5. 多账号随机切换
源码中预留了 cf_account_array 数组,可以配置多个 Cloudflare 账号:
1 | let cf_account_array = [ |
当没有通过环境变量提供 ACCOUNT_ID 和 API_TOKEN 时,Worker 会从这个数组里随机选择一个账号使用。这个设计可以用于简单的多账号分摊,但它不是严格的负载均衡,也不会自动感知账号额度、失败次数或速率限制。
工作原理与架构
CF2OpenAI 的请求链路可以概括为:
1 | OpenAI 兼容客户端 |
源码中的主要处理流程如下:
fetch(request, env, ctx)是 Worker 的入口函数。- 如果是
OPTIONS请求,直接返回 CORS 预检响应。 - 优先读取环境变量
API_KEY、ACCOUNT_ID、API_TOKEN,覆盖代码中的默认配置。 - 如果没有环境变量账号配置,则从
cf_account_array随机选择账号。 - 调用
isAuthorized()校验Authorization请求头。 - 根据路径分发请求:
/v1/models返回模型列表;/v1/chat/completions调用聊天补全代理逻辑;- 其他路径返回
404 Not Found。
- 在聊天补全逻辑中,将客户端传入的
model替换为 Cloudflare 完整模型路径。 - 通过
fetch()请求 Cloudflare 官方 OpenAI 兼容接口。 - Cloudflare 返回成功时,Worker 直接透传响应体;失败时,透传错误状态码和错误内容。
这里的重点是:CF2OpenAI 并不是自己实现一套大模型推理协议,而是利用 Cloudflare 已经提供的 OpenAI 兼容端点,在外面加了一层鉴权、模型映射和 CORS 处理。
安装部署步骤
Cloudflare Workers AI → OpenAI API 适配器
将 Cloudflare Workers AI 转换为兼容 OpenAI Chat Completion 格式的 API 代理,让你可以在任何支持 OpenAI API 的客户端中直接使用 Cloudflare 的免费 AI 模型。
✨ 特性
- 🔄 完全兼容 OpenAI 格式 — 支持
/v1/chat/completions和/v1/models端点 - 🌊 流式 & 非流式 — 自动支持
stream: true/false,由客户端控制 - 🎯 模型短名称映射 — 使用简短名称(如
llama-3.1-8b-instruct)自动映射到 Cloudflare 完整路径 - 🔑 自定义 API Key — 设置自己的鉴权密钥,保护接口安全
- 🔀 多账号负载均衡 — 支持配置多个 Cloudflare 账号,随机切换使用
- ☁️ 零成本部署 — 利用 Cloudflare Workers 免费额度运行
📦 部署指南
前置条件
- 一个 Cloudflare 账号
- 获取你的 Account ID 和 API Token(需要 Workers AI 读写权限)
获取方式:登录 Cloudflare Dashboard → Workers AI → Use REST API → 按提示创建 API Token 并复制 Account ID
步骤一:创建 Worker
- 登录 Cloudflare Dashboard
- 进入左侧菜单 Workers & Pages
- 点击 Create(创建)
- 选择 Create Worker(创建 Worker)
- 为 Worker 取一个名称(如
ai-api-proxy),点击 Deploy(部署)
步骤二:粘贴代码
- 部署后点击 Edit Code(编辑代码)
- 删除默认代码,将
workers.js的全部内容粘贴进去 - 点击右上角 Deploy(部署)
步骤三:配置环境变量(推荐)
为了安全起见,强烈建议通过环境变量配置敏感信息,而不是硬编码在代码中:
- 进入 Worker 的 Settings(设置)→ Variables and Secrets(变量和密钥)
- 添加以下变量:
| 变量名 | 类型 | 说明 |
|---|---|---|
ACCOUNT_ID |
文本 | 你的 Cloudflare Account ID |
API_TOKEN |
密钥 | 你的 Cloudflare API Token |
API_KEY |
密钥 | 自定义的 API 访问密钥(客户端需要使用此密钥) |
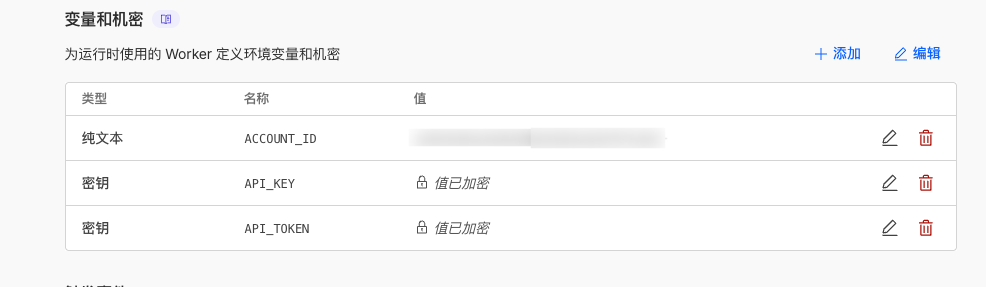
如果设置了环境变量,会自动覆盖代码中的硬编码值。
步骤四:添加 Workers AI 绑定
- 选择绑定
- 添加绑定
- 选择Workers AI,点击添加绑定
- 变量名称填入:AI,点击添加绑定
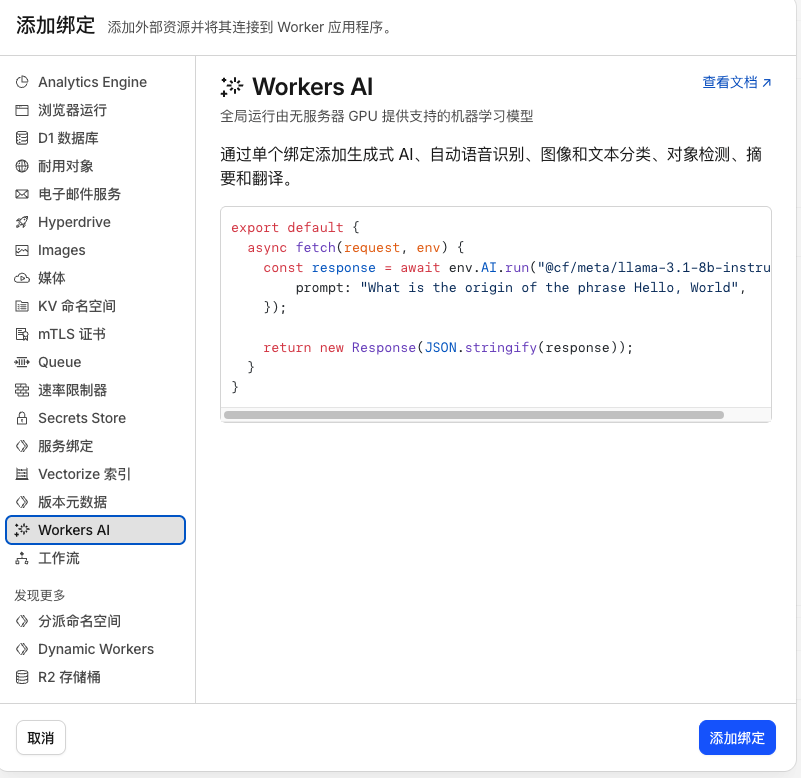
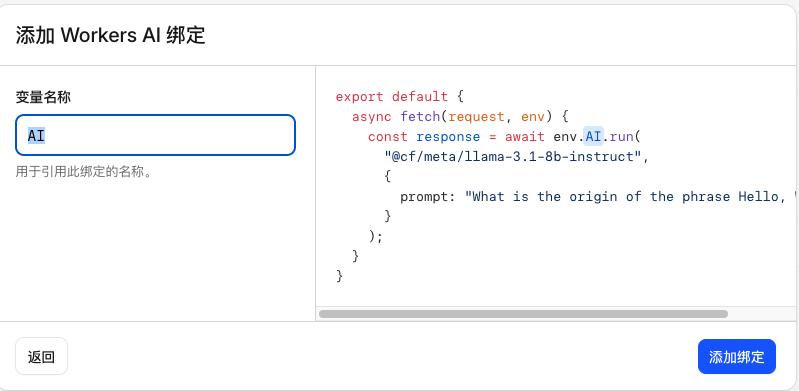
步骤五:验证部署
部署成功后,你的 API 地址为:
1 | https://<你的worker名称>.<你的子域>.workers.dev |
使用 curl 测试:
1 | # 测试模型列表 |
🔧 客户端配置
通用配置
在任何支持 OpenAI API 的客户端中,将以下参数替换为你自己的值:
| 配置项 | 值 |
|---|---|
| API Base URL | https://your-worker.your-subdomain.workers.dev/v1 |
| API Key | 你设置的自定义密钥(如 sk-xxxx) |
| Model | 模型短名称,如 llama-3.1-8b-instruct |
Python (OpenAI SDK)
1 | from openai import OpenAI |
Node.js (OpenAI SDK)
1 | import OpenAI from 'openai'; |
📋 支持的模型
以下为当前配置的模型短名称列表(可在代码中自行增减):
| 短名称 | Cloudflare 模型路径 |
|---|---|
llama-3.1-8b-instruct |
@cf/meta/llama-3.1-8b-instruct |
llama-3.3-70b-instruct-fp8-fast |
@cf/meta/llama-3.3-70b-instruct-fp8-fast |
llama-4-scout-17b-16e-instruct |
@cf/meta/llama-4-scout-17b-16e-instruct |
deepseek-r1-distill-qwen-32b |
@cf/deepseek-ai/deepseek-r1-distill-qwen-32b |
gemma-7b-it |
@hf/google/gemma-7b-it |
mistral-7b-instruct-v0.2 |
@hf/mistral/mistral-7b-instruct-v0.2 |
kimi-k2.5 |
@cf/moonshotai/kimi-k2.5 |
kimi-k2.6 |
@cf/moonshotai/kimi-k2.6 |
| … | 更多模型请查看代码中的 TEXT_GENERATION_MODELS |
完整模型列表请参考 Cloudflare Workers AI Models
🛠 自定义配置
添加新模型
在 workers.js 的 TEXT_GENERATION_MODELS 对象中添加新的映射:
1 | const TEXT_GENERATION_MODELS = { |
修改默认模型
修改 DEFAULT_MODEL 常量:
1 | const DEFAULT_MODEL = 'llama-3.1-8b-instruct'; // 改为你想要的默认模型短名称 |
多账号配置
在 cf_account_array 中添加多个账号,系统会随机选择使用:
1 | let cf_account_array = [ |
❓ 常见问题
Q: 返回 401 Unauthorized?
请检查客户端使用的 API Key 是否与 Worker 中配置的 api_key 一致。
Q: 返回模型相关错误?
请确认使用的模型名称在 TEXT_GENERATION_MODELS 映射表中存在,或者检查该模型是否仍在 Cloudflare Workers AI 中可用。
Q: 如何查看日志?
在 Cloudflare Dashboard 中,进入你的 Worker → Logs(日志),可以实时查看请求日志和错误信息。
Q: 有请求限制吗?
受限于 Cloudflare Workers AI 的免费额度和 Workers 的请求限制,请参考官方文档了解具体限额。
⚠️ 免责声明
本项目仅供学习和研究用途,不得用于任何商业或非法目的。使用者应自行承担使用本项目的一切风险和法律责任。
API Key 安全:请勿将 API Key、Account ID、API Token 等敏感凭证泄露或硬编码在公开仓库中。建议始终使用 Cloudflare Workers 的环境变量 / Secrets 来存储敏感信息。因凭证泄露导致的任何损失由使用者自行承担。
服务可用性:本项目依赖 Cloudflare Workers AI 服务,不保证服务的持续可用性、稳定性或性能。Cloudflare 可能随时更改其 API 接口、定价策略或服务条款。
模型输出:AI 模型生成的内容可能存在不准确、有偏见或不当的情况。使用者应对模型输出进行独立审查和验证,不应将其作为专业建议的替代。
合规要求:使用者有责任确保使用本项目符合所在地区的法律法规,包括但不限于数据隐私保护、内容审查等相关法律要求。
无担保声明:本项目按“现状“提供,不提供任何形式的明示或暗示担保,包括但不限于适销性、特定用途适用性和非侵权性的担保。
使用本项目即表示你已阅读并同意以上免责声明。
📄 许可证
MIT License






